World's Most Expensive Serializer
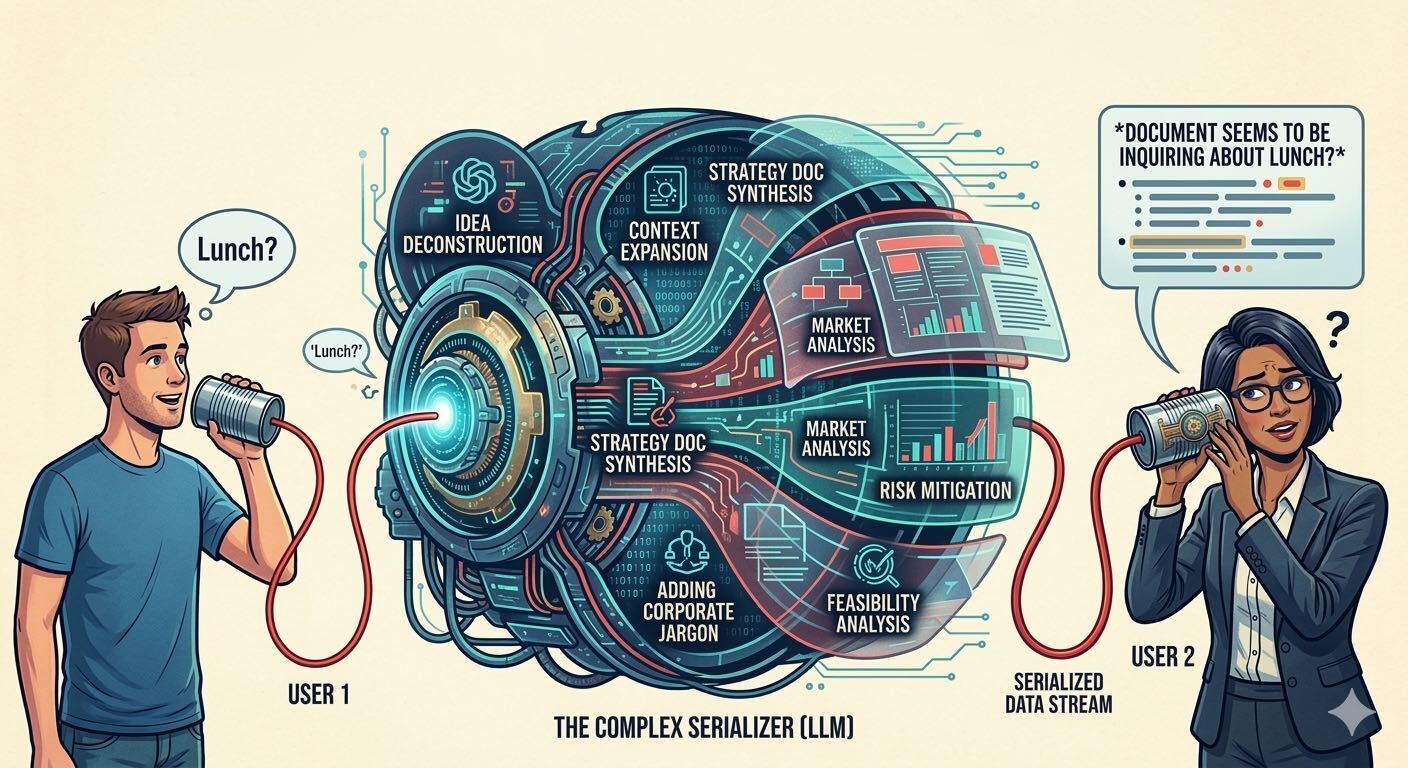
We’ve built the worst serialization library in computing history, and we’re scaling it across every company with an AI first goal.
Let’s sketch this out: A human has a thought. Let’s say: “We should ship this feature faster.” Instead of saying that in a meeting, they open Claude and ask it to write a strategy document. Claude serializes the thought into 2,000 words of corporate prose—complete with key stakeholders, strategic alignment, and a section on driving synergies.
The document gets sent to other humans.
None of them read it.
Instead, they paste it into the agent of their choice and ask for a summary. “Document seems to be advocating for a faster feature shipping cadence.”
We went from thought → expensive token round-trip → same thought and nobody read (needed?) the middle part.
The document isn’t for reading—it’s for having been written. The summary isn’t for understanding—it’s for having been processed.
Both parties can now point to artifacts. “I sent the comprehensive strategy doc.” “I reviewed the materials.” Zero Actual information transferred with all the appearance of progress.
We’ve built tool-shaped objects—things that look like work, smell like work, and generate the same Jira tickets as work, but don’t actually do the thing we pretend they do.
The AI isn’t the problem. The AI is just doing what we asked: making it easier to produce artifacts. We’ve automated the performance of work while carefully preserving all the inefficiency of the actual work. And somehow, we’re calling it productivity.
I am continually shocked at the way large corporations push to automate processes without first asking if the process is worth it. We’ll get their in time because tokens aren’t free, but in the meantime corporate baddies around the world are going to be dealing with the consequences of this, and given the speed with with LLMs can generate content, they’ll be dealing with a whole lot of it.